GET Lightweight Tables or practical tips for designing a database ... / Sudo Null IT News FREE
 In that topic, I would like to talk most rising public presentation when working with tables.
In that topic, I would like to talk most rising public presentation when working with tables.
The topic is not new, but it becomes especially relevant when the database is perpetually development data - the tables become large, and the search and selection for them - tiresome.
Typically, this is callable to a poorly premeditated circuit — not originally designed to handle cosmic amounts of data.
So that the increment of data in the tables does not lead to a step-down in productivity when working with them, it is recommended to adopt a few rules when design the racing circuit.
The first and credibly the most important. Information types in tables should have minimal redundancy.
All data operated by SQL Server, are stored on indeed-called pages that have a unmoving size of 8 Kilobyte. When writing and reading, the server operates happening pages, rather than on separated lines.
Therefore, the more compact data types are put-upon in the table, the fewer pages are required to store them. Few pages - fewer disk trading operations.
To boot to the obvious step-dow in the warhead connected the disk subsystem - in this caseful, there is another advantage - when reading from platter, whatsoever page is first placed in a extraordinary memory area ( Polisher Pool ), and past IT is used for its well-meant intention - to read or modify information.
When using compact information types in Pilo Poolyou can put more data on the same number of pages - due to this we do non waste RAM and reduce the number of logical operations.
Now study a diminished example - a set back that stores information astir the practical days of each employee.
CREATE TABLE dbo.WorkOut1 ( DateOut DATETIME , EmployeeID BIGINT , WorkShiftCD NVARCHAR(10) , WorkHours DECIMAL(24,2) , CONSTRAINT PK_WorkOut1 PRIMARY KEY (DateOut, EmployeeID) ) Are the data types in the table selected correctly? Ostensibly not.
For example, it is very doubtful that there are and then some employees in the enterprise (2 ^ 63-1) that the BIGINT data character was chosen to cover this situation .
We dispatch redundancy and see if the question from such a table is faster?
Make TABLE dbo.WorkOut2 ( DateOut SMALLDATETIME , EmployeeID INT , WorkShiftCD VARCHAR(10) , WorkHours DECIMAL(8,2) , CONSTRAINT PK_WorkOut2 PRIMARY KEY (DateOut, EmployeeID) ) Along the executing plan, you can see the difference in cost, which depends on the ordinary row size of it and the expected number of rows that the query wish return:
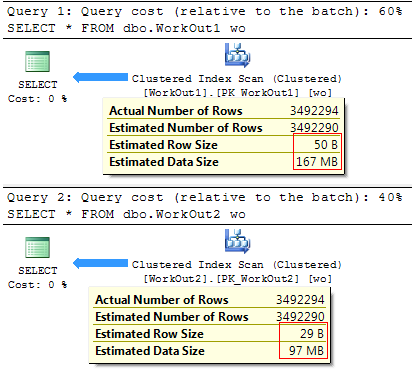
It is very logical that the little the amount of data you need to read, the faster the query will be executed:
(3492294 row (s) moved)
SQL Server Execution Multiplication:
Central processor time = 1919 MS, elapsed time = 33606 ms.
(3492294 row (s) affected)
SQL Server Execution Times:
Central processing unit time = 1420 ms, elapsed time = 29694 ms.
American Samoa you dismiss see, the use of less redundant information types often has a positive effect on query operation and terminate significantly reduce the size of it of trouble tables.
By the way, you can find out the size of it of the table using the following query:
SELECT table_name = SCHEMA_NAME(o.[schema_id]) + '.' + o.name , data_size_mb = Contrive(do.pages * 8. / 1024 AS Denary(8,4)) FROM sys.objects o JOIN ( Blue-ribbon p.[object_id] , total_rows = SUM(p.[rows]) , total_pages = SUM(a.total_pages) , usedpages = Join(a.used_pages) , pages = SUM( CASE WHEN it.internal_type IN (202, 204, 207, 211, 212, 213, 214, 215, 216, 221, 222) THEN 0 WHEN a.[type] != 1 AND p.index_id < 2 THEN a.used_pages WHEN p.index_id < 2 THEN a.data_pages ELSE 0 END ) FROM sys.partitions p JOIN sys.allocation_units a ON p.[partition_id] = a.container_id LEFT JOIN sys.internal_tables it Connected p.[object_id] = IT.[object_id] GROUP BY p.[object_id] ) do ON o.[object_id] = do.[object_id] WHERE o.[case] = 'U' For the tables in question, the query will return the following results:
table_name data_size_mb -------------------- ------------------------------- dbo.WorkOut1 167.2578 dbo.WorkOut2 97.1250 The second govern. Avoid duplication and apply data normalization.
Really, I recently analyzed a database of cardinal costless web service for data formatting T-SQL code. The server part there is identical simple and consisted of one single put of:
CREATE Shelve dbo.format_history ( session_id BIGINT , format_date DATETIME , format_options XML ) Each time during data format, the id of the current academic session, the server system time and settings with which the substance abuser formatted his SQL cypher were saved. And so, the data was used to identify the most popular formatting styles.
With the popularity of the service, the identification number of rows in the tabular array enhanced, and processing format profiles took an increasing amount of time. The reason was the service architecture - with each insertion into the table, a allover circle of settings was saved.
Settings had the following XML structure:
true false lawful 1 true ... true dependable true false ... A total of 450 data format options - each much row in the table took approximately 33Kb. And the daily data growth was more than 100MB. Regular the base grew, and analytics on it began to do yearner.
It turned outer to be simple to fix the situation - all unique profiles were moved to a separate table, where a hash was obtained for each set of options. Starting with SQL Server 2008 , you can use the sys.fn_repl_hash_binary function to do this .
As a resolution, the lap was normalized:
CREATE Remit dbo.format_profile ( format_hash BINARY(16) PRIMARY Key out , format_profile XML NOT NULL ) CREATE TABLE dbo.format_history ( session_id BIGINT , format_date SMALLDATETIME , format_hash BINARY(16) NOT NULL , CONSTRAINT PK_format_history Important KEY CLUSTERED (session_id, format_date) ) And if the proofreading request used to be wish this:
SELECT fh.session_id, fh.format_date, fh.format_options FROM SQLF.dbo.format_history fh Then, to scram the same information in the new scheme, it was indispensable to make a JOIN:
SELECT fh.session_id, fh.format_date, fp.format_profile FROM SQLF_v2.dbo.format_history fh Union SQLF_v2.dbo.format_profile fp ON fh.format_hash = fp.format_hash If we compare the inquiry execution time, and so we wish not see a open advantage from ever-changing the scheme.
(3090 row (s) affected)
SQL Host Execution of instrument Times:
Central processing unit time = 203 ms, elapsed time = 4698 ms.
(3090 row (s) affected)
SQL Host Execution Multiplication:
CPU prison term = 125 ms, elapsed time = 4479 ms.
Simply the goal in that case was pursued some other - to accelerate analytics. And if you had to write a same sophisticated query in front to get a heel of the most popular formatting profiles:
;WITH cte AS ( Choice fh.format_options , hsh = sys.fn_repl_hash_binary(CAST(fh.format_options AS VARBINARY(MAX))) , rn = ROW_NUMBER() OVER (ORDER BY 1/0) FROM SQLF.dbo.format_history fh ) SELECT c2.format_options, c1.cnt FROM ( Superior TOP (10) hsh, radon = MIN(rn), cnt = Enumerate(1) FROM cte GROUP BY hsh ORDER BY cnt DESC ) c1 JOIN cte c2 Happening c1.atomic number 86 = c2.rn ORDER BY c1.cnt DESC That due to data normalization, it became possible to significantly simplify not only the inquiry itself:
Take fp.format_profile , t.cnt FROM ( SELECT Topmost (10) fh.format_hash , cnt = COUNT(1) FROM SQLF_v2.dbo.format_history fh GROUP BY fh.format_hash ORDER BY cnt DESC ) t JOIN SQLF_v2.dbo.format_profile fp Connected t.format_hash = fp.format_hash Only also reduce the execution time:
(10 row (s) affected)
SQL Server Execution Times:
CPU time = 2684 ms, elapsed time = 2774 ms.
(10 course (s) hokey)
SQL Waiter Writ of execution Times:
C.P.U. prison term = 15 ms, elapsed time = 379 SM.
A nice addition was also the diminution in the size of it of the database on the disc:
database_name row_size_mb ---------------- --------------- SQLF 123.50 SQLF_v2 7.88 You can return the size of the data file for the database with the pursuit query:
SELECT database_name = DB_NAME(database_id) , row_size_mb = CAST(Center(CASE WHEN type_desc = 'ROWS' And so size Final stage) * 8. / 1024 AS DECIMAL(8,2)) FROM sys.master_files WHERE database_id IN (DB_ID('SQLF'), DB_ID('SQLF_v2')) GROUP Away database_id I hope, in this object lesson, I was able to show the grandness of normalizing information and minimizing redundancy in the database.
The fractional. Cautiously select the columns enclosed in the indexes.
Indexes terminate significantly speed ahead the selection from the table. Like data from tables, indexes are stored on pages. Consequently. the fewer pages are required to store the index, the faster it can be searched.
It is very important to choose the fields that will be included in the clustered index. Since all the columns of the clustered index are automatically included in each non-clustered (by Spanish pointer).
Quaternary. Use staging and consolidated tables.
Everything is quite simple hither - wherefore make water a complex query from a large table all time, if it is mathematical to make a simple query from a small one.
For example, a data consolidation request is available:
SELECT WorkOutID , CE = SUM(CASE WHEN WorkKeyCD = 'CE' THEN Value END) , DE = SUM(Instance WHEN WorkKeyCD = 'DE' THEN Apprais Close) , RE = SUM(CASE WHEN WorkKeyCD = 'RE' And then Value END) , FD = SUM(CASE WHEN WorkKeyCD = 'FD' THEN Value END) , TR = SUM(CASE WHEN WorkKeyCD = 'TR' THEN Esteem END) , FF = SUM(CASE WHEN WorkKeyCD = 'FF' THEN Value END) , PF = SUM(Instance WHEN WorkKeyCD = 'PF' And then Value END) , QW = SUM(CASE WHEN WorkKeyCD = 'QW' THEN Value Terminate) , FH = Aggregate(CASE WHEN WorkKeyCD = 'FH' And so Value Oddment) , UH = SUM(Subject WHEN WorkKeyCD = 'UH' And then Value END) , NU = SUM(Shell WHEN WorkKeyCD = 'NU' So Value Remainder) , CS = SUM(CASE WHEN WorkKeyCD = 'Atomic number 55' THEN Value END) FROM dbo.WorkOutFactor WHERE Value > 0 GROUP BY WorkOutID If the information in the hold over does not change too often, you can make over a separate table:
Choose * FROM dbo.WorkOutFactorCache And non amazingly, reading from the consolidated table testament be quicker:
(185916 row (s) impressed)
SQL Server Slaying Multiplication:
CPU clip = 3448 ms, elapsed time = 3116 ms.
(185916 row (s) affected)
SQL Server Execution Times:
CPU clip = 1410 ms, elapsed time = 1202 MS.
5th. Each rule has its own exceptions.
I showed a few examples when dynamic data types to fewer redundant ones allows reducing the enquiry execution time. But this is non always the case.
For example, the BIT information type has one feature film - SQL Waiter optimizes the storage of a chemical group of columns of this type happening magnetic disk. For example, if a table has 8 or fewer columns of typeSnatch , they are stored on the page as 1 byte, if there are up to 16 columns of type BIT , they are stored as 2 bytes, etc.
The good news is that the table will take up significantly less space and reduce the number of disk operations.
The invalid news is that when sampling data of this type, implicit decoding will occur, which is rattling demanding happening processor resources.
I bequeath show this with an exemplar. Thither are three selfsame tables that contain employee calendar information (31 + 2 PK columns). All of them take issue only in the information type for consolidated values (1 - went to work, 0 - was absent):
SELECT * FROM dbo.E_51_INT SELECT * FROM dbo.E_52_TINYINT SELECT * FROM dbo.E_53_BIT When using inferior redundant data, the size of the table noticeably decreased (specially the last table):
table_name data_size_mb -------------------- -------------- dbo.E31_INT 150.2578 dbo.E32_TINYINT 50.4141 dbo.E33_BIT 24.1953 But we won't get a significant gain in speed from using the BIT type :
(1000000 row(s) affected) Table 'E31_INT'. Scan count 1, ratiocinative reads 19296, physical reads 1, read-ahead reads 19260, ... SQL Server Execution Times: CPU prison term = 1607 ms, elapsed time = 19962 manuscript. (1000000 row(s) affected) Table 'E32_TINYINT'. Scan count 1, logical reads 6471, physical reads 1, show-ahead reads 6477, ... SQL Host Execution Times: Processor meter = 1029 Ms., elapsed time = 16533 ms. (1000000 row(s) affected) Table 'E33_BIT'. Scan count 1, consistent reads 3109, strong-arm reads 1, read-ahead reads 3096, ... SQL Server Executing Times: CPU time = 1820 disseminated sclerosis, elapsed time = 17121 ms. Although the execution plan will articulate the opposite:
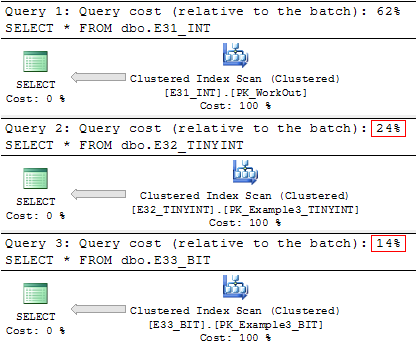
As a result of observations, it was noticed that the negative effect of decryption will not occur if the table contains no more than 8 Second columns.
On the way, information technology is worth noting that in the SQL Server metadata , the BIT data type is utilised very seldom - they often utilise the BINARY character and manually shift to obtain a particular measure.
And the last thing to mention. Edit unnecessary data.
Actually, why doh this?
When fetching data, SQL Server supports a operation optimisation mechanism called read-ahead that tries to predict which data and index pages will be needed to execute the query and puts these pages in the buffer cache before they are really needed.
Consequently, if the put over contains a lot of extra data, this can direct to unnecessary disk operations.
In addition, the removal of unnecessary data allows you to reduce the number of logical operations when reading data from the Buffer Pool - information will be searched and retrieved victimization a littler amount of data.
In conclusion, what I can add - carefully select the information types for the columns in your tables and try to take into account future database dozens.
If you want to portion out this clause with an West Germanic language-speaking audience, please function the translation connec:
Realistic Tips to Reduce SQL Server Database Table Sized
DOWNLOAD HERE
GET Lightweight Tables or practical tips for designing a database ... / Sudo Null IT News FREE
Posted by: singletonworper58.blogspot.com
0 Response to "GET Lightweight Tables or practical tips for designing a database ... / Sudo Null IT News FREE"
Post a Comment